



Transactional databases are excellent at processing transactional workloads but they are not great for conducting large-scale analytics across huge datasets. So ETL which stands for extract, transform and load is a data integration process that integrates data from multiple transactional data sources, cleanses and organizes the data in a way that addresses business intelligence needs and loads the unified data into Enterprise Data Warehouse. The data in Data Warehouse will then be used for Data analytics.
Why ETL is necessary?
It is essential to properly format and prepare data to load it in the data storage system. Along with extracting, transforming, and loading data, it offers several below business benefits.
- Offers deep historical context for business.
- Provides a consolidated view of data that enhances business intelligence solutions for easier analysis and reporting.
- Enables context and data aggregations so that business can generate higher revenue.
- Allows verification of data transformation, aggregation, and calculations rules.
- Allows sample data comparison between source and target system.
- Improves productivity with repeatable processes that do not require heavy hand-coding.
- Improves data accuracy and audit capabilities that most businesses require for compliance with regulations and standards
ETL Architecture
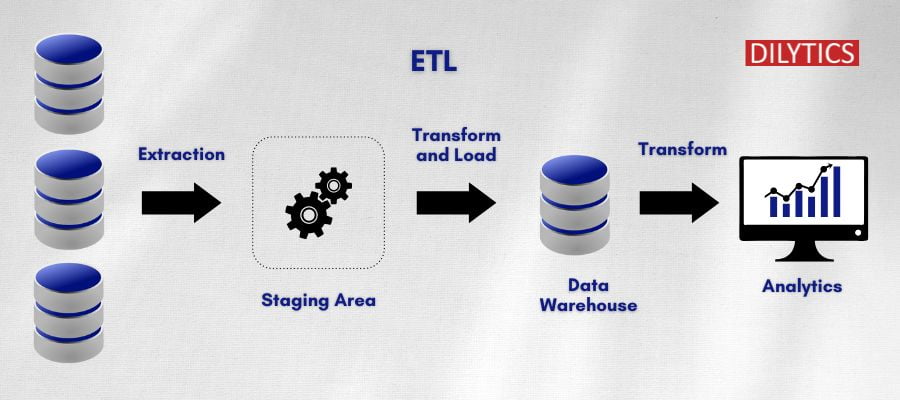
How does the ETL Process work?
Three stages in ETL Process are:
- Data Extraction & Cleansing
- Data Transformation
- Data Loading
Data Extraction
Data can be extracted from Databases, Flat files, Web services and many other sources. If the source system can track the creation date or last modified date of the changes on the records, only the new or changed data will be extracted incrementally from the source system. When the source system is not able to track the newly created or modified records, full extraction of data may be required from the source system. The frequency of the extracts, either it is full or incremental extract, is based on the requirements on how frequently the Data Warehouse must be in sync with the source.
Data Cleansing
Data warehouses require and provide extensive support for data cleaning. ETL Process load and continuously refresh massive amounts of data from a variety of sources so the probability that some of the sources contain dirty data is high. Furthermore, data warehouses are used for decision making, so that the correctness of their data is vital to avoid wrong conclusions. For instance, duplicated or missing information will produce incorrect or misleading statistics. So, data extracted from source systems must be cleansed with the detection and separation of invalid, duplicate, and inconsistent data before it loads to the Data Warehouse. Data cleaning is typically performed in a separate data staging area before loading the data into the warehouse.
Data Transformation
The transformation step in ETL will help to create a structured data warehouse and it happens in the staging area before moving the data into the Data Warehouse. Various ETL tools offer this functionality by supporting proprietary rule languages. A more general and flexible approach is the use of the standard query language SQL to perform the data transformations and utilize the possibility of application-specific language extensions, in particular user defined functions. Some of the transformation steps include
- Merging related information from different source tables into a single Data Warehouse table.
- Mapping of the columns from source to target.
- Establishment of relationships between Data Warehouse tables.
- Creating calculated and derived metrics
- Creating summarization to store the data at summary level
Data Loading
Extracted and transformed data is loaded into the Data Warehouse. Extracted data can be fully loaded into a Data Warehouse table with a bulk mode approach or can be incrementally loaded with a merge approach. Once the data is loaded into fact and dimension tables, it is time to improve performance of the reports that need summary data by creating aggregate tables for summarized data. Snapshot tables can also be created to be able to analyze the reports as of a specific point in time.
Challenges with ETL
Along with many benefits, ETL also comes with challenges that should not be overlooked. If overlooked, they can lead to inefficiencies, performance problems, and operational downtime.
- The amount of data can grow over time and thus leads to many bottlenecks because of the insufficient memory or CPU. ETL Processes need to be scaled up and maintenance costs go up accordingly.
- Ensuring that the data transformed is accurate and complete. If any process in the transformation phase is not done correctly, it results in some data loss, corrupted or irrelevant data.
- Disparate data sources are another challenge with ETL. These can include structured and semi-structured sources, real-time sources, flat files, streaming sources etc. Some of this data is best transformed in batches, while for others, streaming, continuous data transformation works better. Integrating data from each type of these different data sources into a unified Data Warehouse is the biggest challenge.
- Performance of ETL data loads is another biggest challenge. When data needs to be refreshed multiple times a day during business hours, it is especially important to keep the data load window short. So, loading incrementally with processing multiple tasks in parallel can improve the performance.
ETL Tools
There are many commercial ETL tools, Open Source ETL tools and cloud ETL tools to choose from
Open Source ETL tools
Open source ETL tools are a low-cost alternative to commercial ETL tools for many businesses. Some of the best open-source tools available in the market are Hevo data, Apache Camel, Airbyte, Logstash, Pentaho Kettle, Talend Open Studio etc. Limitations of open source ETL tools include lack of support for complex data transformation and desirable features such as change data capture (CDC), lack of compatibility with multiple data sources, lack of error handling capabilities, lack of customer support to handle in- built issues and lack of poor security infrastructure that puts the system at risk.
Batch Processing ETL tools
Businesses use these ETL tools to process the data in batches during off-hours. These tools are designed to focus narrowly on the batch connection of databases in the data Warehouse in batches once or twice a day. This can save time and improves the efficiency of processing the data and helps organizations in managing substantial amounts of data and processing it quickly. Some of the popular batch processing ETL tools are IBM Data Stage, Microsoft SSIS, Oracle Data Integrator, Informatica Power Center etc.
Cloud-Native ETL tools
More and More cloud based ETL applications started to emerge with data moving into the cloud. These Cloud-native ETL applications will extract the data from sources and directly load into a cloud data warehouse. They can then transform data using the power and the scale of the cloud – a critical requirement when you are dealing with Big Data. These ETL tools can be deployed directly into your cloud infrastructure or hosted in the cloud. Some of the popular cloud native ETL tools are Fivetran, Matillion, Snaplogic, Stich Data etc
Real Time ETL Tools
Most modern applications need a real-time access to data from various sources. For example, when a picture is uploaded to the Facebook account, it must be seen immediately by friends, but not a day later. This Real-time demand increasingly requires the data to be processed in real time, with a distributed model and streaming capabilities, rather than in batches. Some of the popular Real time ETL tools include StreamSets, Confluent, Alooma, Striim etc
Traditional ETL or Modern ELT?
Traditionally, an ETL tool extracts data from several Online Transaction Processing (OLTP) databases into a staging area which is an intermediate storage between the data source and the data target. In that staging area, the ETL tool helps cleansing, transforming, and optimizing the data for analysis. The ETL tool then loads the data into a Data Warehouse. This data in Data Warehouse will be queried by the Data Visualization tools to generate reports that help businesses make decisions and set strategy. Despite the usefulness of ETL tools, the ETL process is still complicated and hence requires a team of data professionals to develop ETL Pipelines and automate the process for the data in Data Warehouse to be up to date with the source systems.
Modern data analytics (ELT), on the other hand, has become increasingly more popular with the adoption of cloud databases. Cloud ELT is built to leverage the best features of a cloud data warehouse i.e., elastic scalability, parallel processing of many jobs. It is useful for handling high-volume, enormous amounts of unstructured datasets as loading can occur directly from hundreds of sources. It is more ideal for big data management since it does not need much upfront planning for data extraction and storage. For Example, powerful cloud data warehouses such as Amazon Redshift, Snowflake, and Google Big Query do not need an ETL server to perform transformations. The transformations are done within the Cloud Data Warehouse itself.
If you are still on-premises and the data is coming only from few data sources, traditional ETL still works. However, cloud ELT has become increasingly popular as more businesses are moving on to cloud architectures.
ETL vs ELT Comparison
Category | ETL | ELT |
Cost | Expensive. Need to invest in hardware. | Cost Effective. No need to invest in hardware. Cloud providers offer pay as you go plans. |
Maturity | Has been in the market around 30 years. So, it is more mature and reliable. | Has been in the market in the recent years. Not much matured. |
Types of Data | Structured Data | Structured, Semi Structured and Unstructured data |
Maintenance | Requires higher maintenance. Need to maintain the hardware. | Requires little maintenance. Cloud providers take care of the maintenance. |
Data Lake | Is not compatible | It is compatible |
Data Volume | ETL can easily handle small datasets with complex transformations | ELT can handle large datasets |
Data Load | Transformed data is loaded to the target database | Source data is loaded to the target database and transformed within the target database |
Compliance | Sensitive information can be removed before loading data to target. So, it satisfies GDPR, HIPAA, and CCPA compliance standards | All the source data will be loaded to target without removing sensitive information. So, it could violate GDPR, HIPAA, and CCPA compliance standards |
Target Types | On-Premise Data Warehouse or Cloud Data Warehouse | Cloud Data Warehouse or Data lakes |
Conclusion
In conclusion, ETL processes are complicated, but the benefits of having a standardized process can make it worth the effort. ETL is often necessary even for small companies and being aware of best practices will help ensure that your business does not miss anything and that you are giving yourself a solid foundation to grow on.
Many businesses have spent years developing their systems to work exactly right for their business needs. And do you want to be the same? Spending many years in this research? do not worry, DiLytics can help you with it.
All you must do is check out our site for numerous services and contact us at [email protected]. It is as simple as that and you will have the best services in your hand.
